Paper: Accelerating Inference for Sparse XMR Trees

Published in the Proceedings of the Web Conference 2022
Introduction
In this paper we study how to accelerate inference for sparse extreme multi-label ranking (XMR) tree models. Tree-based models are the workhorse of many modern search engines and recommender systems. Tree-based models have many advantages over their neural network counterparts. First, they are extremely fast to train: many models can be trained in minutes as opposed to days for neural networks. They are also very quick when it comes to inference, as the bulk of the inference consists of sparse linear algebra multiplications. Furthermore, they also take up substantially less memory. In enterprise-scale applications, these benefits mean tremendous savings in compute and storage. However, there is always room for improvement. In particular, while the scientific community has devoted much attention to the optimization of dense linear algebra kernels for neural networks, they have devoted significantly less attention to the optimization of sparse linear algebra kernels for tree-based models. In order to fill this gap in the literature, we will propose a class of sparse linear algebra kernels that we call masked sparse chunk multiplication (MSCM) techniques. These kernels are tailored specifically for XMR tree models and drastically improve performance anywhere from x8 to x20 on our benchmark models. The technique drives inference for Amazon's Predictions for Enormous and Correlated Output Spaces (PECOS) model framework, where it has significantly reduced the cost of both online and batch inference.
Extreme Multi-Label Ranking Trees
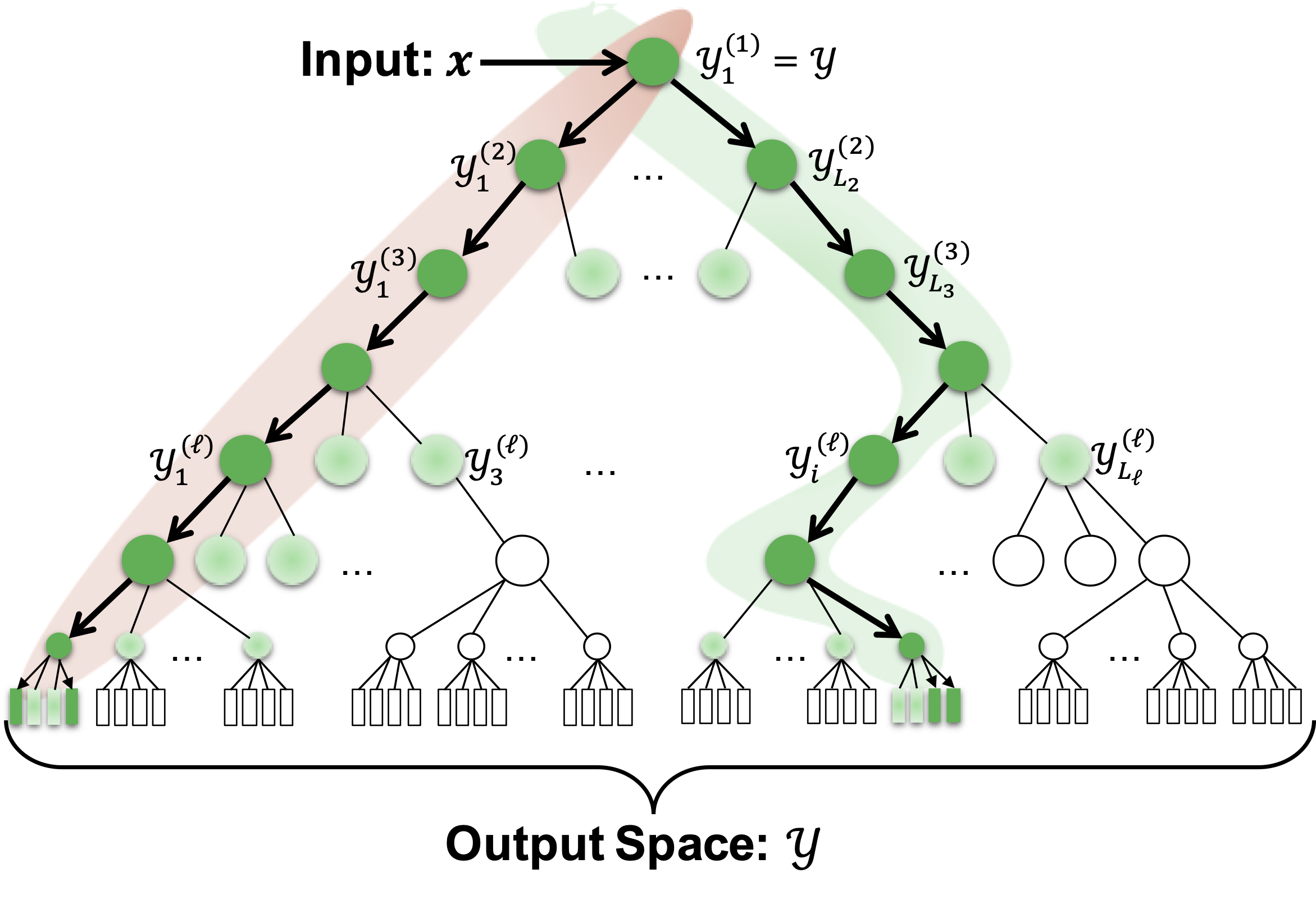
An XMR problem can be characterized as follows: given a query
A linear XMR tree model is a hierarchical linear model that constructs a hierarchical clustering of the labels
Every layer of the model has a ranker model that scores the relevance of a cluster
where
At subsequent layers, rankers are composed with those of previous layers, mimicking the notion of conditional probability; hence the score of a cluster
where
As a practical aside, the column weight vectors
where
i.e., it is one when
Inference and Beam Search
In general, there are two different inference settings:
- Batch Inference: inference is performed for a batch of
queries represented by a sparse matrix where every row of is an individual query . - Online Inference: a subset of the batch setting where there is only one query, e.g., the matrix
has only one row.
When performing inference, the XMR model
The act of batch inference entails collecting the top
However, the act of exact inference is typically intractable, as it requires searching the entire model tree. To sidestep this issue, models usually use a greedy beam search of the tree as an approximation. For a query
Masked Sparse Chunk Multiplication
Our contribution is a method of evaluating masked sparse matrix multiplication that leverages the unique sparsity structure of the beam search to reduce unnecessary traversal, optimize memory locality, and minimize cache misses. The core prediction step of linear XMR tree models is the evaluation of a masked matrix product, i.e.,
where
Observations in the paper about the structure of the sparsity of
where each chunk
We identify each chunk

To see why this data structure can accelerate the masked matrix multiplication, consider that one can think of the mask matrix
where the block column partition is the same as that in the definition of the column chunked weight matrix
Therefore, since
Hence, for all mask blocks
where
We remark that it remains to specify how to efficiently iterate over the nonzero entries
- Marching Pointers: The easiest method is to use a marching pointer scheme to iterate over
and for . - Binary Search: Since
can be highly sparse, the second possibility is to do marching pointers, but instead of incrementing pointers one-by-one to find all intersections, we use binary search to quickly find the next intersection. - Hash-Map: The third possibility is to enable fast random access to the rows of
via a hash-map. The hash-map maps indices to nonzero rows of . - Dense Lookup: The last possibility is to accelerate the above hash-map access by copying the contents of the hash-map into a dense array of length
. Then, a random access to a row of is done by an array lookup. This consumes the most memory.
There is one final optimization that we have found particularly helpful in reducing inference time --- and that is evaluating the nonzero blocks
Performance Benchmarks
There are more thorough performance benchmarks in the paper. But for this blog post, I will simply show a side by side comparison of our Hash MSCM implementation against a Hash CSC implementation of an existing XMR library, NapkinXC. Since NapkinXC models can be run in PECOS (our library), we have an apples-to-apples performance comparison. We measure performance on several different data sets:

Note that thanks to MSCM, our implementation is around 10x faster than NapkinXC. See the full text for more exhaustive performance analysis.