Paper: Operator Shifting for Noisy Elliptic Operators


Published in Springer Research in the Mathematical Sciences
Introduction
In this paper, we examine linear systems corrupted by noise and consider the problem of how to improve the accuracy of linear solves using statistical techniques. In essence, we suppose that we have a linear system of the form
where
using only our noisy sample
In the literature there are a number of existing techniques for producing better
we might instead solve the linear problem with regularization
where
Our Approach
In contrast, our paper considers the above problem from the point of view of statistical estimation of
where
where
In this respect, the approach is reminiscent of James-Stein estimation, except applied to matrix inverses instead of vector quantities. Like Stein estimation, the key to the approach is to try to estimate the shift factor
where
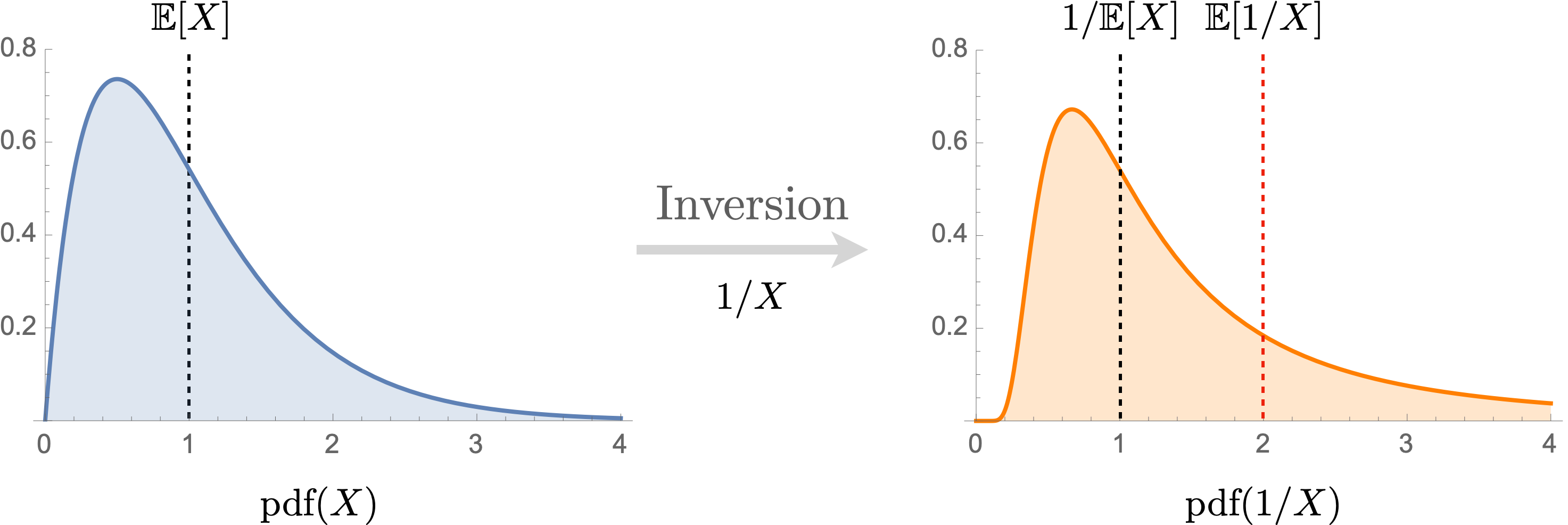
-
First, note that inversion is a convex operation. If we have a random variable
and we use to attempt to estimate the quantity , we will actually potentially overshoot by a very substantial amount, as seen in the figure above. Indeed, strict Jensen's inequality tells us that . The same fact also applies to matrices. If and are always positive semi-definite matrices, then it can be shown and hence the naive estimator will overshoot on average. We therefore interpret operator shifting as an attempt to correct this bias. -
The second reason is the same reason why James-Stein estimation works. Recall that the error of an estimator can be decomposed into error from bias and error from variance (see Bias-Variance Tradeoff). Therefore, not only can we expect operator shifting to not only reduce the bias of the naive estimator (as noted in (I)), but we can also expect it to reduce the variance as well! Furthermore, unlike the James-Stein setting, the reduction of bias and variance are not even in conflict with each other. In this sense, operator shifting is basically a free lunch as it works to reduce both bias and variance simultaneously.
Indeed, one of the fundamental results (Theorem 4.2) we show in the paper is that under mild assumptions one can expect an optimal shift factor to always fall within the range
Note that the quantity
Estimating the Optimal Shift Factor
Note that solving the fundamental optimization problem
is unfortunately not possible because we do not know
However, this quantity involves
and that each
Conclusion
We show in the paper that using this technique can substantial reduce error in a number of computations involving noisy Graph Laplacians. However, the scope of the paper is limited to elliptic (i.e., symmetric positive definite) operators. We also study the case of general matrices in a separate paper. Needless to say, the case of general matrices admits substantially less mathematical theory due to a number of interesting pathological cases that can cause strange behavior in the estimation problem. If the reader is interested, we recommend reading our blog post on the follow-up paper.